
Most of us understand the concept behind Artificial Intelligence (AI) but do not really know how to implement AI into our own companies. We think AI is for big global tech companies only, like Tesla who are building self-driving cars. On that note, advances in AI are allowing Tesla to push for vision only based autonomous vehicles, and not to rely solely on other sensors or mapped environments. This will allow these smart vehicles to drive anywhere and not only in the large cities.
One can do weird and wonderful things with AI but we are not all big conglomerates like Tesla. AI however is capable of moving us into the future. It can be implemented in farming, factories, security, robotics, transportation, and smart retail etc.
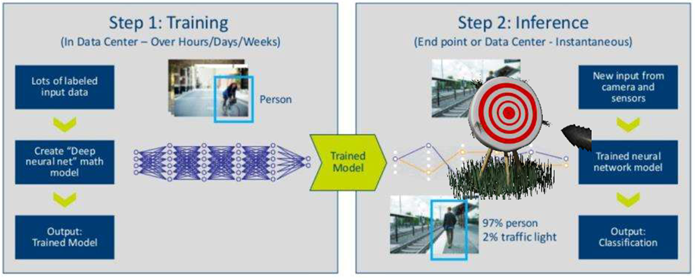
The current trend is to follow a two-step approach. Step 1 is to create the “logic” or decision-making model. This is called training and typically relies on super computers to analyse masses of data for long periods of time. Luckily many of these models have been pre-generated and are available to software developers requiring them only to tweak (or configure) these models as needed.
Step 2 is applying or using these trained models. This is called Inference. The Collins dictionary’s definition of Inference is “drawing a conclusion about something by using information that you already have about it”. The current approach is to implement this “at the edge” or close to the sensor (video camera for example). This saves a lot of time and bandwidth by not sending the raw data back to a central server to be processed.
Demand for edge AI hardware of all types, from wearables to embedded systems, is growing fast. One estimate sees unit growth at over 20% per year reaching over 2.2 billion units by 2026. The big challenge for edge AI inference platforms is to process high bandwidth data and make real-time decisions while being physically small, drawing low power and being affordable.
There are a number of companies making the core processing components used in Inference AI type systems. The major players are Nvidia and Intel with solutions from Google and Kneron also being used in the embedded field. Intel has a couple of core AI chips with the most common being the Movidius Myriad X which is roughly 8 x 9 mm in size.
Board level manufacturing companies have implemented this chip in embedded modules such a mini-PCIe and M.2 making it possible to add entry level AI Inference capabilities to embedded PCs such as the IONN Alpha series (or any other compatible system) with matching mini-PCIe or M.2 slots.

For more powerful AI Inference solutions suppliers have added a number of these Myriad X AI cores onto one PCIe card. For example, the Mustang-V100-MX8 from IEI with 8 of these cores.
Nvidia has similar sized cards called their Quadro series. There are different sub series and model numbers of these cards giving different levels of performance. Normally these cards are used in servers to provide GPU capabilities to multiple virtual PCs (VMs) supported by the server.

These cards are technically similar to the normal gaming (or Bitcoin mining) GPU cards used in normal PCs. There are software tools available to assist with AI implementations based on these cards. In general, Nvidia Quadro series cards will provide the most AI power (most CUDA cores) in a larger Embedded PC enclosure. If you need optimal AI power and small size, and low power consumption is not important, then you should consider systems based on these cards. Currently the Quadro T1000 and RTX A4000 series is available from CME.

VCNT1000-PB

VCNRTXA4000-PB
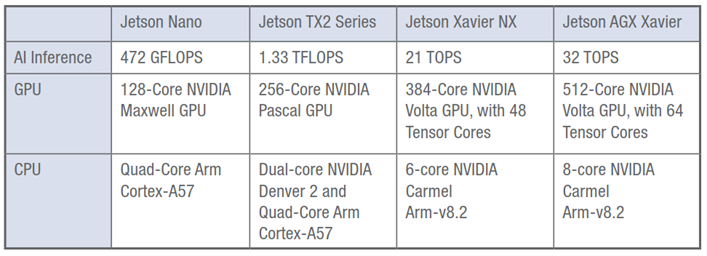
Nvidia has another product series called Jetson. This series was specifically designed for AI Inference implementation at the edge and it includes a powerful ARM processor (CPU) together with the AI core unit (GPU) on a card called a SOM or System on Module. No PC is required. Currently there are 4 Jetson modules called the NANO, TX2 NX, Xavier NX and the AGX Xavier giving 128/256/384 and 512 Cuda cores. The Xavier NX with 384 Cuda cores currently provides the best value for money.

There is numerous pre-trained AI software modules available from Nvidia which can be tweaked or configured as required for actual Inference applications. Nvidia also have Development kits for their Jetson SOM modules which can be used for software development and testing.

While being OK for software testing, these development kits are not ideal for real world applications. To address this a number of Embedded PC suppliers have developed AI Inference systems based on these Nvidia Jetson SOM modules with added USB3, LAN, POE etc ports all packaged in robust enclosures. They also replace the active cooling fan with passive cooling for added reliability.
Aaeon is an example of a supplier with a wide range of these AI systems. They have systems with different LAN, POE, USB3 etc configurations. The BOXER-82543AI comes with 1x LAN, 2x POE, 4x USB3 ports and provision for optional WLAN/LTE modules inside and antenna holes in the enclosure. These systems currently support Linux 18.04 LTS and many can be fitted with additional internal SSD storage.
For your own small sized AI inference project all you need is something like this BOXER system together with an in-house tweaked or configured pre-trained AI Inference model (from Nvidia or the internet) and some general software development to present the data in a meaningful way and to process the information accordingly. These units also have multiple GPIO (digital IO) ports which can be used to control external systems as and when needed.





